5 – Digitalisering i letevirksomheten
Olje- og gassforekomstene blir stadig vanskeligere å finne. Teknologiutvikling og digitalisering har gitt bedre data og verktøy som har bidratt til økt forståelse av geologien og gjort det mulig å identifisere nye letekonsepter.
Digitalisering gir også nye muligheter både til å redusere letekostnader og effektivisere arbeidsprosesser. Dette kan bidra til redusert leterisiko og flere funn.
Innenfor letevirksomheten er det lang tradisjon for å håndtere store datamengder gjennom innsamling og prosessering av seismikk, geologisk tolkning og boring av letebrønner. Leting etter olje er en industri som har flyttet grenser for digital teknologi.
Seismiske undersøkelser genererer enorme mengder data, og noen av de største regnemaskinene (supercomputere) og regneklyngene som til enhver tid er å oppdrive, brukes til prosessering og analyse. Avansert modellering og simulering, 3D-visualisering og automatisert geologisk tolkning har i en årrekke vært en del av verktøykassen til fagfolkene i letemiljøet.
Leting etter olje og gass
flytter grenser for digital teknologi
Økende datamengder
Datamengende vokser raskt
OD har ansvar for å ha kunnskap om petroleumspotensialet på norsk sokkel, være et nasjonalt sokkelbibliotek og spre fakta og kunnskap. Dette betyr blant annet at OD skal gjøre informasjon og data i alle faser av virksomheten enkelt tilgjengelig og formidle fakta og faglig kunnskap til myndigheter, næring og samfunnnet for øvrig (Figur 5.1). ODs mangeårige arbeid med å samle inn og gjøre data og informasjon offentlig tilgjengelig blant annet på ODs Faktasider, har gitt norsk sokkel et konkurransefortrinn i forhold til mange andre petroleumsprovinser, hvor det er mer krevende å få tilgang til data.
Databasen for seismikk og brønndata på norsk sokkel, Diskos (Faktaboks 5.1), inneholder om lag 10 tusen terrabyte (10 petabyte) data (per 31.12.2019) og vokser raskt (Figur 5.2 og Figur 5.3). De store datamengdene utgjør et unikt grunnlag for analyse av mulighetene som kan bidra til at det gjøres nye funn.
Figur 5.1 Faktaformidling.

Figur 5.2 Utvikling i seismikk datavolum i Diskos, 1994-2019.
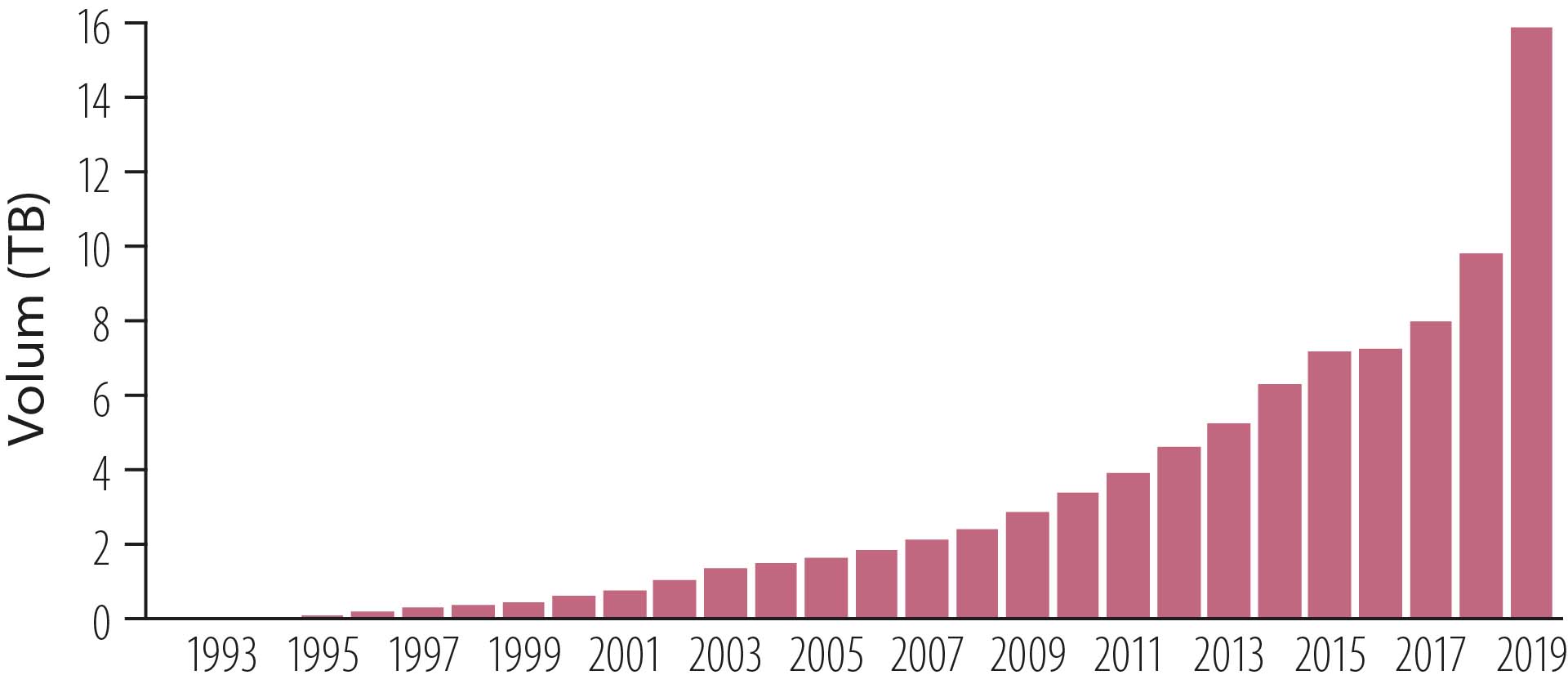
Figur 5.3 Utvikling i brønndata volum i Diskos, 1994-2019.
Tilgjengeliggjøring av data
Stordataanalyser i form av maskinlæring og bruk av kunstig intelligens kan bringe fram ny informasjon og ny innsikt. Mer og bedre data, verktøy og metoder kan gi økt forståelse av geologien i undergrunnen og gjøre det mulig å identifisere nye letekonsepter. Dette forutsetter enkel tilgang på digitale data.
Data må tilgjengeliggjøres
for alle og tilrettelegges for å
være lesbare for maskiner
Datainnsamling og teknologiutvikling i over 50 år fra norsk sokkel har resultert i en rekke ulike programvarer for håndtering av dataene og et mylder av filformater, databaser og lagringssystemer med dårlig innbyrdes kompatibilitet.
Resultatet er at data vanskelig lar seg hente ut av ett system for å benyttes i et annet, og data fra ulike fagdisipliner er tungvinte å sammenstille for analyse på tvers. I tillegg kan dataene ofte være dårlig strukturert og ha mangelfull metainformasjon, noe som gjør det vanskelig å se sammenheng mellom objekter og vurdere datakvalitet.
Både lagringsformatene og kvaliteten på dataene kan hindre effektive stordataanalyser. For å utnytte verdipotensialet som ligger i kunstig intelligens og stordataanalyse, er det avgjørende at dataene er lett tilgjengelige for bruk.
Dataene må derfor tilrettelegges, det vil si overføres til et format som kan brukes av alle og som maskinene kan lese. Innsatsen som må til for å tilrettelegge data er undervurdert, og må prioriteres, dersom verdipotensialet skal realiseres.
Det er satt i gang flere prosjekter for å bedre datakvaliteten og gjøre dataene maskinlesbare. Et eksempel er at rettighetshaverne på norsk sokkel, gjennom Norsk olje og gass, har satt i gang et prosjekt for å digitalisere borekaks data fra om lag 1500 brønner. Dataene gjøres digitalt tilgjengelige i Diskos.
Faktaboks 5.2 Maskinlesbare prøvedata
Faktaboks 5.3 AVATARA - Avansert augmentert analyserobot for palynologi
OD har også deltatt i et prosjekt sammen med Oil and Gas Authority (OGA) og Oil and Gas Technology Centre (OGTC) i Aberdeen for å se på analysemetoder som kan levere vurderinger av strukturerte og ustrukturerte brønndata, raskt og nøyaktig. Målet er å bruke dataene til å identifisere og klassifisere intervaller som kan indikere tilstedeværelse av oversette petroleumsforekomster (Faktaboks 5.4). En del av prosjektet er å organisere og rense data slik at de kan brukes i analyser.
Det jobbes intensivt hos flere aktører i bransjen med å etablere dataplattformer som kan frigjøre data fra de opprinnelige formatene og lagringssystemene og bedre tilgjengeligheten for applikasjoner. Sentrale elementer her er utvikling av robuste og standardiserte datamodeller og programmeringsgrensesnitt (API) for datautveksling.
Flere av de større selskapene har gått sammen og etablert den skybaserte plattformen «Open Subsurface Data Universe (OSDU)», som raskt har fått stor oppslutning. Målet er at alle globale lete-, produksjons- og brønndata skal være tilgjengelig i samme format på en dataplattform. Dette vil blant annet kunne gi enda bedre muligheter for stordataanalyser og enda bedre datagrunnlag for maskinlæring og kunstig intelligens. Gruppen har raskt fått tilslutning, og den har nå 133 medlemmer fordelt på olje-, service- og teknologiselskaper. BP, Chevron, ConocoPhillips, Equinor, ExxonMobil, Hess, Marathon Oil, Noble Energy, Pandion Energy, Shell, Total, Woodside og Schlumberger er blant medlemmene.
Faktaboks 5.4 OGTC/OGA/NPD-prosjektet
Stordataanalyse
Stordataanalyse har vokst fram som følge av behovet for å kunne bruke de enorme datamengdene som skapes for å finne trender, mønster og mening ut av data. Dette gjøres ofte uten binding til bestemte datasett, men heller på tvers av datasett. Denne utviklingen har skjedd over tid som beskrevet i (Figur 5.9 [17]). Mange av disse teknikkene eller metodene blir beskrevet som "data mining", "machine learning" og "deep learning" og er varianter innenfor kunstig intelligens (Artificial Intelligence, AI).
Generelt refererer "data mining" til prosessen med å trekke ut informasjon eller kunnskap fra rådata. Maskinlæring (ML) er et underfelt i det større feltet kunstig intelligens og viser til bruk av spesifikke algoritmer for å identifisere mønstre i rådata og presentere sammenhengen i dataene som en modell. Slike modeller (eller algoritmer) kan deretter brukes til å gjøre slutninger om nye datasett eller veilede beslutninger.
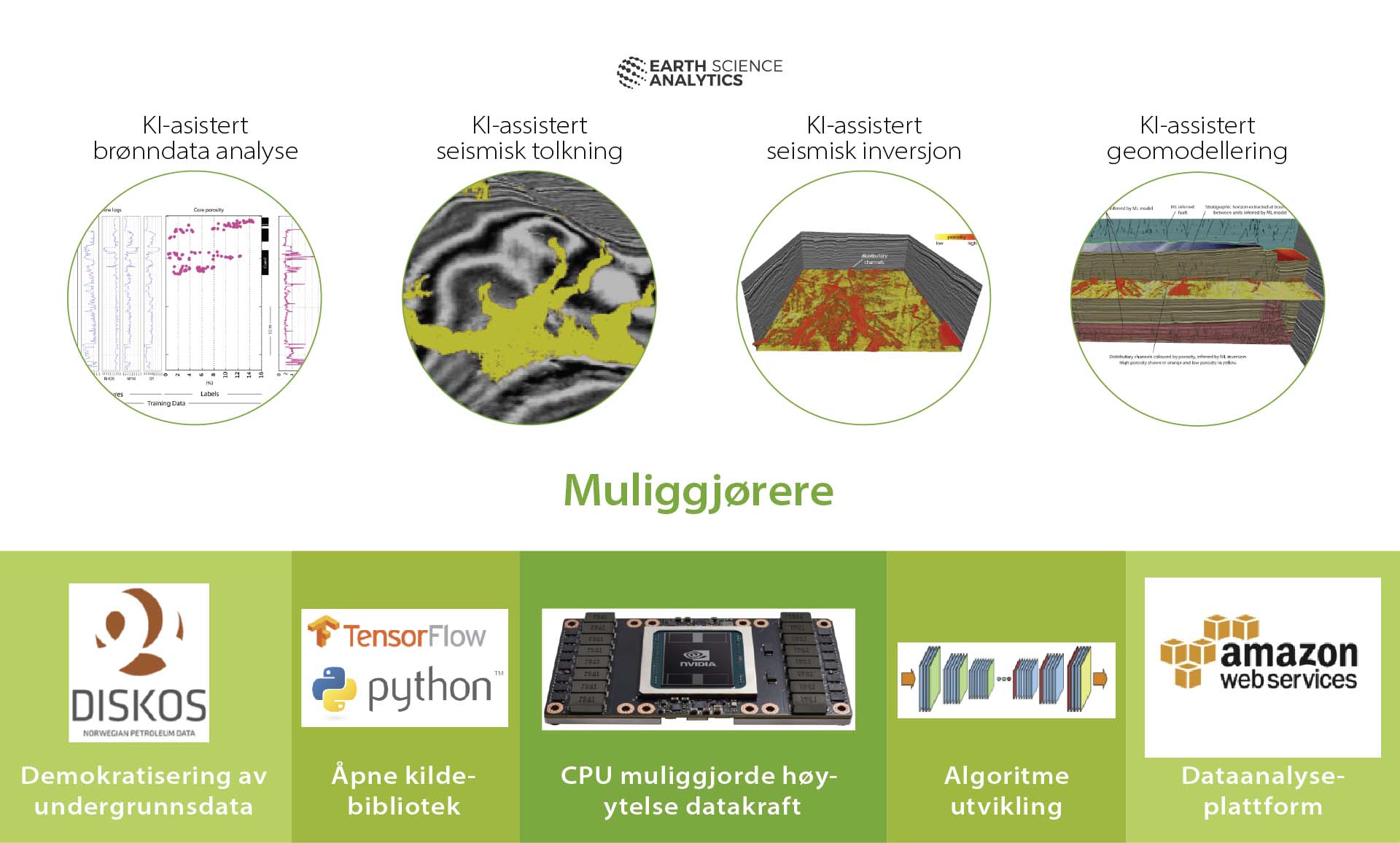
ML er et kjent begrep innenfor leting, et eksempel er autotolkning av seismikk som har eksistert i mange år og er illustrert i Figur 5.10. Maskinlæringsmodeller kan også lages ut fra brønndata og brukes til å forutsi reservoaregenskaper i undergrunnen. ML kan også bistå til å forbedre ufullstendige datasett ved å forutsi manglende data.

Figur 5.9 Kunstig intelligens og dataanalyse. Kilde: modifisert etter Earth Science Analytics og Nvidia blog (2018).

Figur 5.10 Automatisert seismisk tolkning. Kilde: Lundin Energy.
Betydelig verdipotensiale
Realisering av verdipotensialet
Trolig er det fram til nå kun skrapt i overflaten av hva som er mulig å få til gjennom digitalisering i letevirksomheten for å redusere usikkerheten, øke leteeffektiviteten og finne mer olje og gass. Den raske utviklingen de siste årene viser at stadig flere aktører er i ferd med å få øynene opp for mulighetene, og det er etterhvert stor enighet i næringen om at det er et betydelig potensial for digitalisering.
Men for å lykkes er det ikke nok at aktørene investerer i egne prosjekter. De må også kunne samarbeide, både med partnere og konkurrenter, være villig til å dele data, kunnskap og teknologi og til og med vurdere egen forretningsmodell og rolle i markedet. Det kan også være utfordringer ved bruk av data, for eksempel i ML-sammenheng, på grunn av IP (Åndsverksloven), selv når data ikke lenger er taushetsbelagt.
Det er viktig at industrien og myndigheter kan komme fram til løsninger og bidrar til at frigitte data blir mest mulig åpne. Konsekvensen av mangel på åpne data kan bli at verdipotensialet ikke realiseres eller at det tar lang tid før potensialet kan tas ut (Faktaboks 5.5).
Selskaper må samarbeide og
være villig til å dele data,
kunnskap og teknologi
Myndighetene har også en viktig rolle i både å bidra til å tilrettelegge og dele data og kunnskap, slik at verdiskapingen for samfunnet skal bli størst mulig (Faktaboks 5.6).
I kjølvannet av KonKraft-rapporten (Faktaboks 5.5) har det vært økt oppmerksomhet om deling av ulike typer data og effektene av dette. Myndighetene har vurdert hvorvidt statusrapportene (Faktaboks 5.7) bør offentliggjøres.
Faktaboks 5.5 KonKraft (Konkurransekraft på norsk sokkel)
Faktaboks 5.6 Verdier ved deling av data - større for samfunnet enn for det enkelte selskap
Offentliggjøring av statusrapporter kan bidra til mer kostnadseffektiv leting. Det vil bedre datatilgangen for selskaper som vurderer å søke om tildeling i områder som tidligere har vært tildelt. Videre vil det sikre et minimum av erfaringsoverføring fra forrige rettighetshavergruppe til den neste, samt formidle informasjon om nyere data og studier som nye rettighetshavere kan vurdere å anskaffe. Etter hvert som en større del av norsk sokkel blir mer moden, vil nye utvinningstillatelser stadig oftere omfatte areal som har vært konsesjonsbelagt én eller flere ganger (Figur 2.13).
I noen tilfeller får selskap tildelt areal som allerede har vært grundig evaluert av tidligere rettighetshavere. Enkelte ganger kan det være fornuftig at ny rettighetshaver gjør en re-evaluering av området med nye tilnærminger. I andre tilfeller kan en slik re-evaluering vise seg å være en duplisering av tidligere arbeid, som ikke tilfører ny kunnskap. Frigiving av statusrapporter kan bidra til mer kostnadseffektiv leting ved at nye rettighetshavere og andre drar nytte av arbeid og erfaringer som er gjort i tidligere tillatelser i samme område.
Dette vil bidra til økt effektivitet i letevirksomheten, både gjennom et økt idemangfold og konkurranse, og gjennom redusert leterisiko, noe som gir en samfunnsøkonomisk gevinst. OED har lagt ut forslag til endring i petroleumsforskriften deriblant frigivning av statusrapporter med høringsfrist 1. november 2020.
Figur 5.11 Faktorer for å realisere verdipotensial knyttet til digitalisering i letefasen. Kilde: modifisert etter Earth Science Analytics (2018).
Demokratisering av undergrunnsdata
På norsk sokkel ligger det meste til rette for at slike samfunnsøkonomiske gevinster kan realiseres. De viktigste faktorene er illustrert i Figur 5.11 [17]. Allmenn og enkel tilgang til undergrunnsdata gjennom OD, Diskos og andre kilder gjør det mulig for fagmiljøene å eksperimentere med nye analysemetoder og -teknikker og bygge datavitenskap inn i sine modellapparat. Dette forutsetter at næringen er enige om standarder som sikrer interoperabilitet (Faktaboks 5.8), og sørger for at funksjoner som ligger i selskapsspesifikke systemer kan koples sammen.
Det vil si at flyten av data mellom aktører og applikasjoner gjøres enklere, at tolkning av delte data støttes og at nytten av samlede datasett på tvers av selskaper og partnerskap blir gjort tilgjengelig. Krav til interoperabilitet sikrer at aktørene i næringen unngår å bli avhengige av enkeltleverandører av plattformer og dermed unngår å bli låst inne i teknologivalg.
Faktaboks 5.8 Interoperabilitet
Åpne kildebibliotek
I tillegg er det blitt mer vanlig å frigi kildekoder, og det har dukket opp både generelle og geoscience-spesifikke "open source" biblioteker. Tilgang på slike biblioteker av åpne kildekoder gjør det betydelig enklere å bruke ML i de geovitenskaplige analysene innenfor leting.
Algoritmeutviklinger
Det store omfanget av data i moderne datasett har gitt en eksplosjon av nye metoder og teknikker for å hente ut informasjon. Industrien har derfor tilgang til en voksende "ny leverandørindustri" gjennom et kompetent økosystem av utviklere og selskaper som utvikler nye algoritmer blant annet basert på den økende mengden undergrunnsdata. Den eksisterende leverandørindustrien har også tatt i bruk nye digitale verktøy og nye arbeidsmetoder. I tillegg tilbyr de store skyselskapene avanserte verktøy og tjenester for å analysere og modellere store datasett.
Dataanalyseplattform
Det finnes også svært mange ulike plattformer med data, som inneholder viktig informasjon om undergrunnen på norsk sokkel. Å samle disse plattformene inn under én stor åpen plattform vil trolig gjøre datatilgangen mer effektiv. På en slik plattform kan det brukes avansert maskinlæring og algoritmer for å koble utallige databaser sammen i et slags knutepunkt.
Datakraft
De nye metodene for stordataanalyse er gjort mulig blant annet gjennom rask utvikling i datamaskinenes prosessorkraft og -hastighet, og gjennom å samle datamaskinkraften for å forbedre ytelsen (kjent som High-Performance Computing, eller HPC). Skyselskapene tilbyr i økende grad høy-ytelse (HPC) databehandlingsevne blant annet for å optimalisere dataanalyse og forhåpentligvis framskynde tiden fra leting til første olje- eller gassproduksjon.
Dersom svært store datamengder skal behandles, eller data krever store parallelle beregninger, vil det være behov for større regneressurser (tungregning) som det fram til nå har vært mest kostnadseffektivt å etablere i et supercomputersenter ([19]).
Superdatamaskiner innebærer store investeringer, men kan ifølge industrien redusere tiden fra tildeling av en utvinningstillatelse til funn med mange måneder og redusere kostnadene betydelig ved å bore færre tørre brønner. Ettersom etablering av supercomputere gir stordriftsfordeler, er det innenfor petroleumssektoren hovedsakelig de store aktørene som har etablert egne datasenter hvor de bruker supercomputere. Disse supercomputerne går normalt for full kapasitet hele døgnet.
Både Eni, Total og Petrobras har oppgradert sine superdatamaskiner den senere tid og økt regnekraften betydelig. I tillegg til de store oljeselskapene er seismikkindustrien store brukere av egne supercomputere til prosessering av seismikk. Mindre oljeselskaper som bare trenger stor datakraft i perioder, leier datakraft enten i skyen eller hos spesialiserte aktører.