Results of the FORCE 2020 lithology machine learning competition

329 teams from around the world signed for the competition. 148 of them submitted at least one solution. 2200 solutions were scored against the blind well dataset of 10 wells. In the end there can only be 1 winner.
The FORCE 2020 Machine predicted Lithofacies competition results
And the winner is…..
...the human with the machine
- Olwale Ibrahim, an applied geophysics student from the Federal University of Technology in Lagos, Nigeria won the competition.
- In second place is the GIR team a research team from Universidade Estadual do Norte Fluminense (UENF), located in Macaé, Brazil. The effort was headed by Lucas Aguiar
- In third place came the Lab ICA Team at the Pontifical Catholic University of Rio de Janeiro which was headed by Smith W. A. Canchumuni. Laboratotio de Inteligencia Computacional Aplicada PUC-Rio
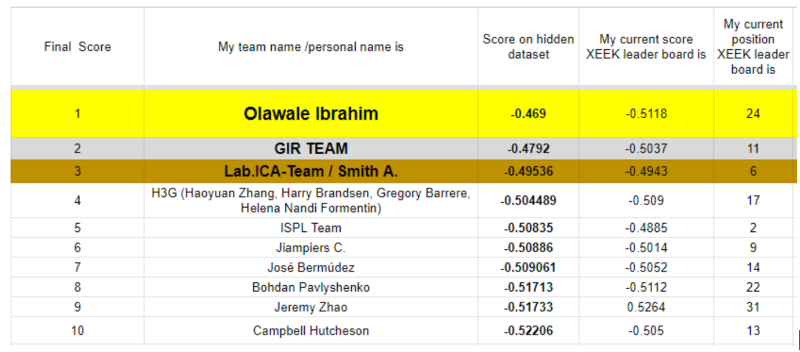
As expected the final scores are significantly different on the blind dataset to as compared to the test data. This is a combined effect of the models being overfitted to the data and the blind data not having the same lithology distribution as the combined train and test data (later more on that...).
The final scores are incredibly close and when looking at the predictions on the well logs one realises how little difference there is between the top 5-7 models. One can therefore safely say that the top 7 teams are actually all winners.
Download the full report here!
All data, submitted machine learning codes and final scores are here: https://github.com/bolgebrygg/Force-2020-Machine-Learning-competition
Confusion matrix of the winning model for all wells in the blind /train / test dataset
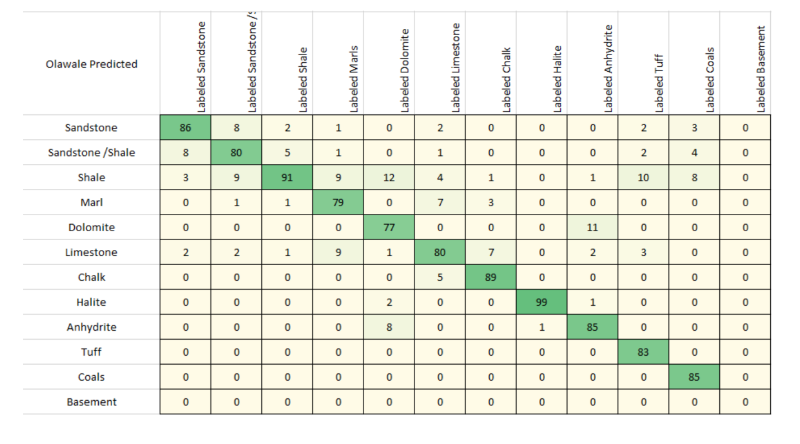
Please read the in depth analysis of the outcomes here
https://docs.google.com/document/d/13XAftsBVHIm01ZN0lP56Q4hZ9hgdYR1G_6KeV2DdzOA/edit?usp=sharing
Conclusions from a regional geologists point of view. Should we use this machine generated data? (personal view of peter bormann)
It appears that the machine provides something like a 80-95% percent solution in most cases. It can be questioned if a 100% solution can ever be achieved given the systemic uncertainty in assigning lithology labels in the first place.
Real ground truth data is hard to come by, with core data being too biased towards sands and the cuttings data suffering from vertical resolution loss.
With this respect it is also not surprising that no team managed to get much above the 80% score on the blind dataset. The 80% may represent the combined uncertainty in the input labels, the log curves and the rocks types that escape absolute definitions. I am however hopeful that this postulation will be challenged in the future.
Comparing the machine predictions to inhouse data and vendor purchased data I came to conclude that the machine predictions offer an extremely valid second opinion and often highlight the very clear shortcoming in these large databases that have been curated, somewhat inconsistently, over the past 50 years.
I think this competition is exemplary on how machine learning can both effectivize and enrich our geoscience workflows. Running all models over a data set and then analysing agreement and disagreement with the original labels or interpreters opinions offers an effective way of ploughing through large datasets while at the same time helping with ideation.
One can analyse for example if the machine predicted missed sand is real and if it turns out to be real start to dream about new exploration opportunities.
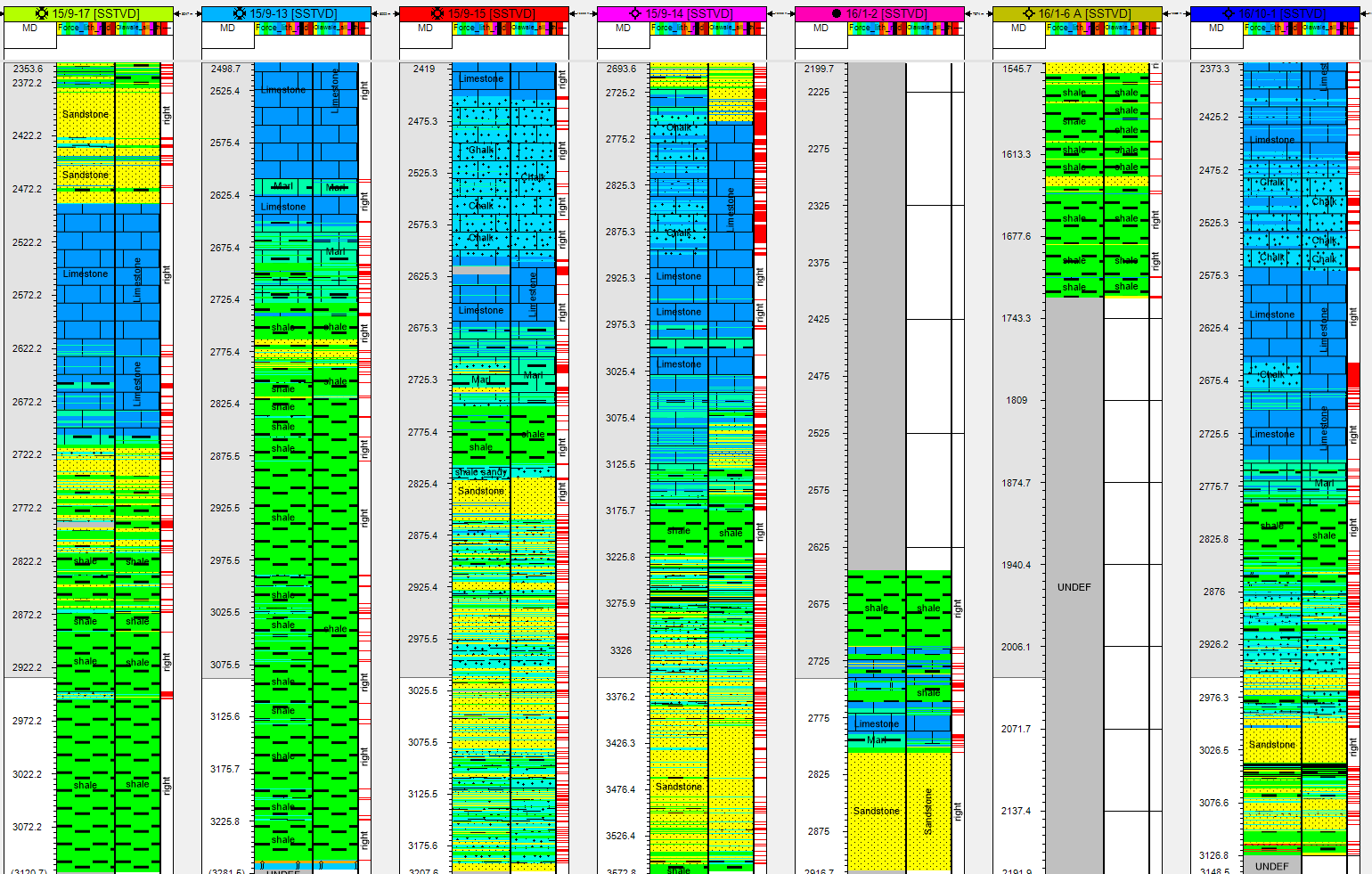
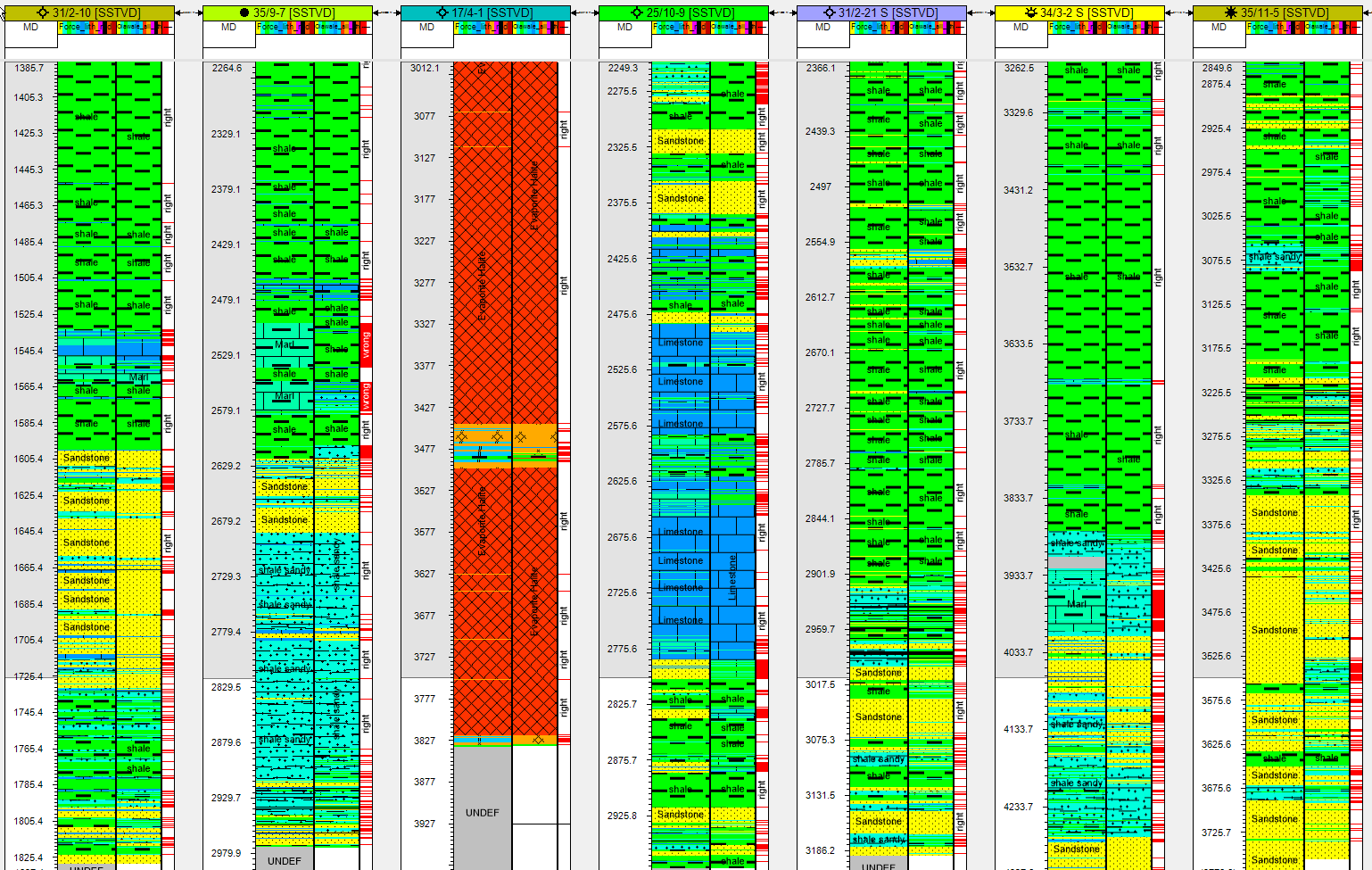
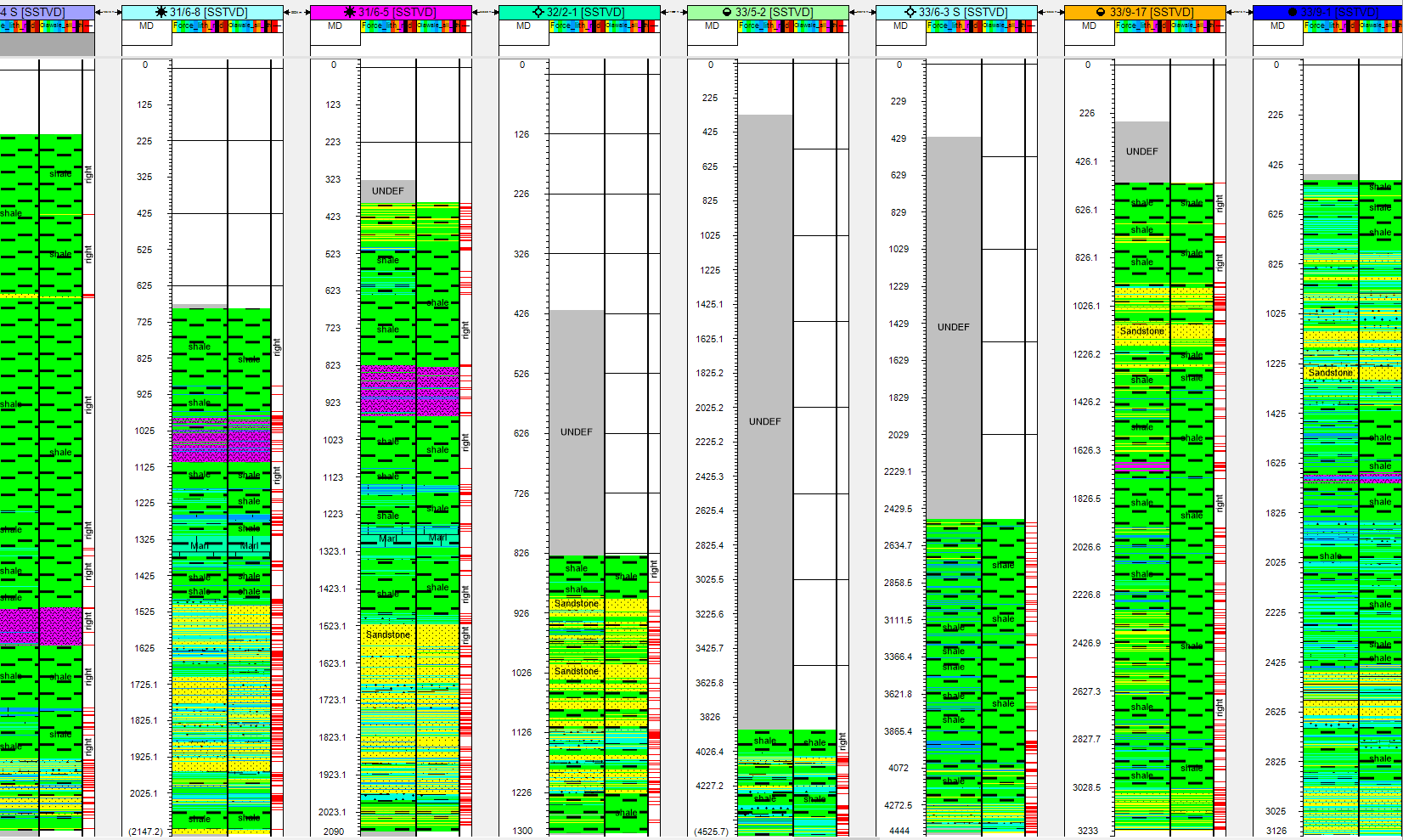
Examples of the wells verus the prediction (Force Label on the Left /Olawale prediction on the right) (blind/test train wells)
Updated: 11/19/2022